Overview
In today’s fast-evolving AI landscape, new models emerge daily, pricing structures change, and performance improvements happen constantly. Building applications tightly coupled to a single LLM provider creates technical debt and limits your ability to adapt.
This guide explores an architecture pattern that allows you to easily switch between different LLM providers like OpenAI (ChatGPT), Anthropic (Claude), and Google (Gemini) without rewriting your entire codebase. You’ll learn how to design flexible systems that are testable, maintainable, and future-proof.
The Problem: Tight Coupling
Like many developers, I typically start with direct integration:

This approach works initially, but creates several problems:
- Vendor lock-in - You’re dependent on one AI company’s availability and pricing
- Difficult migrations - Changing providers means rewriting code throughout your application
- Hard to test - Testing requires real API calls, making unit tests slow and expensive
- No fallback options - If the AI service goes down, your application breaks
- Limited flexibility - Can’t easily compare different models or use the best one for each task
The Solution: Interface-Based Architecture
The key is creating a common interface that all LLM providers must implement. This abstraction layer decouples your application logic from specific provider implementations.
Step 1: Define a Common Interface
First, define a shared contract that all LLM providers must follow:

This interface typically includes methods like generate(), stream(), and embeddings() that every provider must implement.
Step 2: Implement Provider-Specific Adapters
Create concrete implementations for each AI provider:

Each adapter handles provider-specific details like authentication, request formatting, and error handling while exposing the same interface.
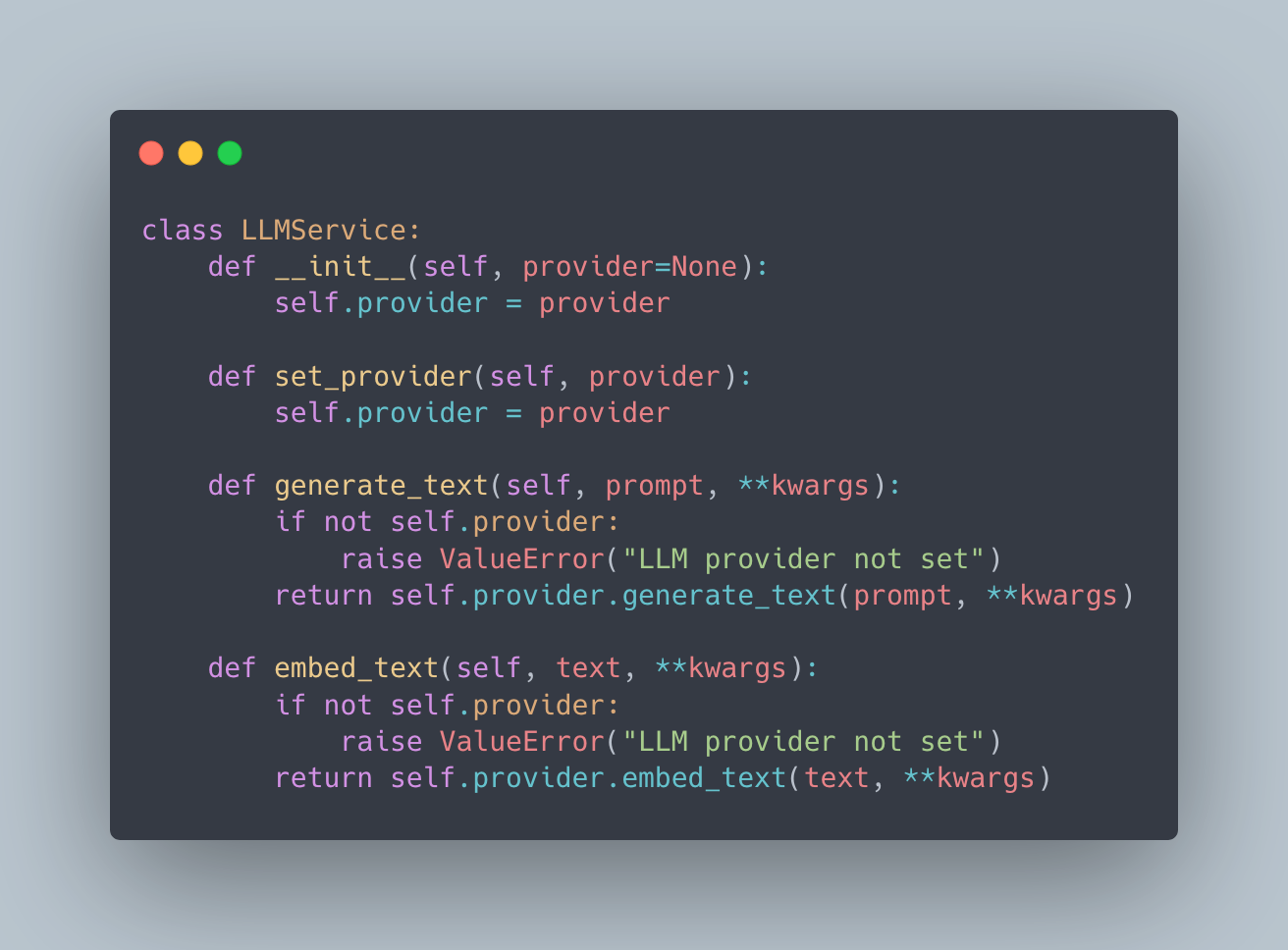
Step 3: Build Your Application Service
Your application service depends only on the interface, not concrete implementations:

This means you can swap providers by changing which adapter you inject, without modifying your business logic.
Step 4: Add Configuration-Based Selection
Keep provider settings in a configuration file for maximum flexibility:

Now you can change providers by simply updating a config file - no code changes required.
Testing Benefits: This architecture simplifies testing significantly. You can create mock provider classes to simulate API responses, enabling thorough unit testing without making live API calls or incurring costs.
Advanced Patterns
Once you have the basic swappable architecture in place, you can implement sophisticated patterns that leverage multiple providers simultaneously.
Task-Based Provider Selection
Route different types of tasks to the most appropriate provider:

For example: use Claude for complex reasoning, GPT-4 for creative writing, and Gemini for multimodal tasks. Your application selects the optimal provider based on the task type.
Multi-LLM Consensus
Get responses from multiple providers and synthesize them for higher-quality results:

This pattern works well for critical decisions where you want multiple “opinions” before proceeding.
Fallback Chain
Implement automatic failover when a provider is unavailable:

Your application tries providers in order until one succeeds, ensuring high availability even during outages.
A/B Testing Providers
Compare different providers in production to make data-driven decisions:

Track metrics like response quality, latency, and cost to optimize your provider selection over time.
Benefits of This Architecture
Flexibility and Control:
- Easy switching - Change AI models without modifying application code
- Multi-provider strategy - Use different providers for different tasks based on their strengths
- Backup plans - Automatic failover if one provider is down or rate-limited
- Cost optimization - Choose providers based on price-performance ratio for each use case
Quality and Reliability:
- A/B testing - Compare responses from different providers to find the best match
- Consensus patterns - Combine multiple models for higher-quality outputs
- Gradual migrations - Test new providers in production with minimal risk
Development Experience:
- Testability - Mock providers for fast, free unit testing
- Future-proof - Easily add new providers as they emerge
- Reduced technical debt - Clean abstractions prevent vendor lock-in
Summary
In today’s rapidly evolving AI landscape, building applications that can easily switch between different LLM providers isn’t just a nice-to-have - it’s essential for maintaining competitive advantage and operational flexibility.
Key takeaways:
- Use interfaces/abstractions to decouple your application from specific providers
- Implement adapters for each provider while maintaining a common contract
- Leverage configuration to change providers without code changes
- Build advanced patterns like fallbacks, consensus, and A/B testing for production resilience
Start with the basic interface pattern, then add advanced patterns as your needs grow. Your future self will thank you when the next breakthrough model launches or pricing changes force a migration.
Looking for more architecture content? Check the architecture tag for related posts.